XGBoost — это интегрированный алгоритм машинного обучения., который можно использовать для различных задач, таких как регрессия, классификация и сортировка, и широко используется в соревнованиях по машинному обучению и в промышленных областях. Успешные примеры включают в себя: классификацию текста веб-страницы, прогнозирование поведения клиентов, анализ настроений, прогнозирование рейтинга кликов по рекламе, классификацию вредоносных программ, классификацию элементов, оценку рисков и крупномасштабное прогнозирование процента отсева онлайн-курсов.
XGBoost — одна из самых глубоких моделей для начинающих. Она соединяет точки знаний, такие как дерево решений, бустинг и GBDT. Всем настоятельно рекомендуется попробовать. В этой статье я будуПроисхождение и преимущества XGBoost, принцип модели и вывод оптимизации, анализ параметров модели XGBoost, пример настройки параметров, визуализация XGBoostПредставьте XGBoost и так далее. Напоминаю, XGBoost — это усовершенствование на базе GBDT.Для прочтения этой статьи необходимо иметь определенное представление о GBDT.Незнакомые студенты могут прочитать предыдущую статью:Получите машинное обучение за 100 дней | Day58 Введение в машинное обучение: жесткий демонтаж GBDT
Происхождение и преимущества XGBoost
В моделировании данных часто используется метод Boosting, объединяющий сотни или тысячи древовидных моделей с низкой точностью классификации в прогностическую модель с высокой точностью. Модель будет повторяться непрерывно, создавая новое дерево с каждой итерацией. Однако, когда набор данных сложный, могут потребоваться тысячи итераций, что приведет к огромным вычислительным узким местам.
В ответ на эту проблему XGBoost (eXtreme Gradient Boosting), разработанный доктором Ченом Тяньци из Вашингтонского университета, реализует параллельное построение деревьев регрессии с помощью многопоточности на основе C++ и улучшает исходный алгоритм Gradient Boosting, тем самым значительно улучшая скорость обучения модели и точность прогноза.
Основные преимущества XGBoost заключаются в следующем.:
1. GBDT использует информацию о производной только первого порядка во время оптимизации, XGBoost использует производные как первого, так и второго порядка, а также поддерживает пользовательские функции потерь при условии, что функция потерь может быть производными первого и второго порядка;
2. Добавлен регулярный член для контроля сложности модели и предотвращения переобучения;
3. Опираясь на практику случайного леса, он поддерживает выборку столбцов (случайный выбор признаков), что может не только уменьшить переобучение, но и сократить вычисления;
4. При поиске наилучшей точки сегментации реализован метод аппроксимации, а также учитывается обработка разреженных наборов данных и пропущенных значений, что значительно повышает эффективность алгоритма;
5. Поддержка параллелизма;
6. Алгоритм приближенной гистограммы для эффективного создания точек-кандидатов на сегментацию;
7. В реализации алгоритма сделано множество оптимизаций, что значительно повышает эффективность работы алгоритма.При недостатке памяти используются идеи блокировки, предварительной выборки, сжатия и многопоточной кооперации.
Принцип и оптимизация модели XGBoost
XGBoost на самом деле является своего рода GBDT или аддитивной моделью и алгоритмом прямой оптимизации.
аддитивная модельДругими словами, сильный классификатор формируется путем линейного добавления ряда слабых классификаторов. Общая комбинация выглядит следующим образом:в,является слабым классификатором один за другим,- оптимальный параметр, изученный слабым классификатором,— доля слабого обучения в сильных классификаторах, а P — всеиКомбинация. Эти слабые классификаторы добавляются линейно, чтобы сформировать сильный классификатор.
шаг впередТо есть в процессе обучения классификатор, созданный в следующем раунде итераций, обучается на основе предыдущего раунда. То есть его можно записать в таком виде:
Как выглядит модель XGBoost?
- где К - количество деревьев.
- дерево регрессии,, удовлетворять
- q представляет структуру каждого дерева, которое сопоставляет экземпляр обучающей выборки с соответствующим конечным индексом.
- Т - количество листьев на дереве.
- Каждый соответствует независимой древовидной структуре q и весу листа w.
- это функциональное пространство, состоящее из всех деревьев регрессии.
В отличие от деревьев решений, каждое дерево регрессии содержит непрерывную оценку на каждом листе, которую мы используем для представления оценки на i-м листе. Для данного экземпляра выборки мы используем правила принятия решений для дерева (заданное q), чтобы классифицировать его по листьям, и вычисляем окончательный результат путем суммирования оценок соответствующих листьев (заданных w) предсказанного значения.
Изучение XGBoost
Чтобы изучить эти наборы функций в этой модели, мы будемРегуляризованная целевая функция для минимизации:
в:— функция потерь, есть 2 общих:
Функция квадратичных потерь:
Функция потерь логистической регрессии:
: термин регуляризации, используемый для наказания сложных моделей во избежание переобучения обучающих данных. Обычно используемые закономерности - это регулярность L1 и регулярность L2:
Закономерность L1 (лассо):
L2 регулярность:
Следующий шаг — изучить целевую функцию, каждый раз сохранять исходную модель неизменной и добавлять новую функцию.в нашу модель.
\begin{split}\text{obj}^{(t)} & = \sum_{i=1}^n l(y_i, \hat{y}i^{(t)}) + \sum{i=1}^t\Omega(f_i) \ & = \sum_{i=1}^n l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i)) + \Omega(f_t) + \mathrm{constant}\end{split}
\begin{split}\text{obj}^{(t)} & = \sum_{i=1}^n (y_i - (\hat{y}i^{(t-1)} + f_t(x_i)))^2 + \sum{i=1}^t\Omega(f_i) \ & = \sum_{i=1}^n [2(\hat{y}_i^{(t-1)} - y_i)f_t(x_i) + f_t(x_i)^2] + \Omega(f_t) + \mathrm{constant}\end{split}
\begin{align*} f(x) &= \sum_{n=0}^\infty\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n \&= f(x_0) +f^{1}(x_0)(x-x_0)+ \frac{f^{2}(x_0)}{2}(x-x_0)^2 + \cdots + \frac{f^{(n)}(x_0)}{n!}(x-x_0)^n \end{align*}
\begin{split}\text{obj}^{(t)} &\approx \sum_{i=1}^n [g_i w_{q(x_i)} + \frac{1}{2} h_i w_{q(x_i)}^2] + \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2\ &= \sum^T_{j=1} [(\sum_{i\in I_j} g_i) w_j + \frac{1}{2} (\sum_{i\in I_j} h_i + \lambda) w_j^2 ] + \gamma T\end{split}$$
Это выглядит немного сложно, пусть:,, приведенная выше формула упрощается до:
В приведенной выше формуленезависимы друг от друга,является квадратным термином. для определенной структуры, мы можем рассчитать оптимальный вес:
будетПодводя к приведенной выше формуле, расчетные потери оптимального решения:
\begin{align*} gain=\underbrace{\frac{G_L^2}{H_L+\lambda}}{оценка левого узла} + \ underbrace {\ frac {G_R ^ 2} {H_R + \ lambda}}{оценка правого узла}-\underbrace{\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}}_{перед сегментацией}-\gamma \конец{выравнивание*}
\начать{выравнивать*} \начать{массив}{л} \text{Модель прогнозирования:}F(x)=\sum_{i=1}^Tw_if_i(x)\ \text{Целевая функция: }obj^t=\sum_{i=1}^NL(y_i,F_i^t(x_i))+\Omega(f_t)\
\because obj^t=\sum_{i=1}^NL(y_i,F_i^t(x_i))+\Omega(f_t)\\
~~~~~~~~~=\sum_{i=1}^NL(y_i,F_i^{t-1}(x_i)+w_tf_t(x_i))+\Omega(f_t)\\
\text{由泰勒公式: }f(x+\Delta x)\thickapprox f(x)+\nabla f(x)\Delta x+\frac{1}{2}\nabla^2 f(x)\Delta x^2\\
\therefore obj^t\thickapprox\sum_{i=1}^N[L(y_i,F_i^{t-1}(x_i))+\nabla _{F_{t-1}}L(y_i,F_i^{t-1}(x_i))w_tf_t(x_i)\\
~~~~~~~~~~~~~~~\frac{1}{2}\nabla _{F_{t-1}}^2L(y_i,F_i^{t-1}(x_i))w_t^2f_t^2(x_i)]+\Omega(f_t)\\
\text{令 $g_i=\nabla _{F_{t-1}}L(y_i,F_i^{t-1}(x_i))$}\\
~~~~~~h_i=\nabla _{F_{t-1}}^2L(y_i,F_i^{t-1}(x_i))\\
~~~obj^t\thickapprox \sum_{i=1}^N[L(y_i,F_i^{t-1}(x_i))+g_iw_tf_t(x_i)+\frac{1}{2}h_iw_t^2f_t^2(x_i)]+\Omega(f_t)\\
\because L(y_i,F_i^{t-1}(x_i)) \text{ 是常量}\\
\therefore \text{目标函数:}\\
~~~obj^t=\sum_{i=1}^N[g_iw_tf_t(x_i)+\frac{1}{2}h_iw_t^2f_t^2(x_i)]+\Omega(f_t)+C\\
\text{用叶子节点集合以及叶子节点得分表示 ,每个样本都落在一个叶子节点上:}\\
f_t(x)=m_q(x),~~m\in R^T,~~q:R^d\rightarrow\{1,2,3,...,T\}\\
\Omega(f_t)=\gamma T+ \frac{1}{2}\lambda \sum_{i=1}^Tm_j^2,\\
\text{$T$ 是第 $t$ 棵树叶子结点总数}\\
\text{$m_j$ 是第j个叶子结点的权重}\\
\text{定义第 $j$ 个叶子节点所在的样本为 $I_j=\{i|j=q(x_i)\}$}\\
\text{新的目标函数:}\\
obj^t=\sum_{i=1}^N[g_iw_tf_t(x_i)+\frac{1}{2}h_iw_t^2f_t^2(x_i)]+\Omega(f_t)\\
~~~~~~~=\sum_{i=1}^N[g_iw_tm_q(x_i)+\frac{1}{2}h_iw_t^2m_q^2(x_i)]+\gamma T+ \frac{1}{2}\lambda \sum_{i=1}^Tm_j^2\\
~~~~~~~=\sum_{j=1}^T[(\sum_{i \in I_j}g_i)w_tm_j+\frac{1}{2}(\sum_{i \in I_j}h_iw_t^2+\lambda )m_j^2]+\gamma T\\
\text{令: $G_j=\sum_{i \in I_j}g_i$ , $H_j=\sum_{i \in I_j}h_i$ }\\
obj^t=\sum_{j=1}^T[G_jw_tm_j+\frac{1}{2}(H_jw_t^2+\lambda)m_j^2]+\gamma T\\
\text{对二次函数优化问题:}\\
m_j^*=-\frac{G_j^2w_t}{H_jw_t^2+\lambda}\\
obj^*=-\frac{1}{2}\sum_{j=1}^T\frac{G_j^2w_t^2}{H_jw_t^2+\lambda}+\gamma T\\
\text{令 $w_t=1$ :}\\
m_j^*=-\frac{G_j}{H_j+\lambda}\\
obj^*=-\frac{1}{2}\sum_{j=1}^T\frac{G_j^2}{H_j+\lambda}+\gamma T\\
\text{所以当我们新增一个切分点增益为:}\\
gain=\underbrace{\frac{G_L^2}{H_L+\lambda}}_{左节点得分}+\underbrace{\frac{G_R^2}{H_R+\lambda}}_{右节点得分}-\underbrace{\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}}_{切分前得分}-\gamma
\end{array}
\end{align*}
$$
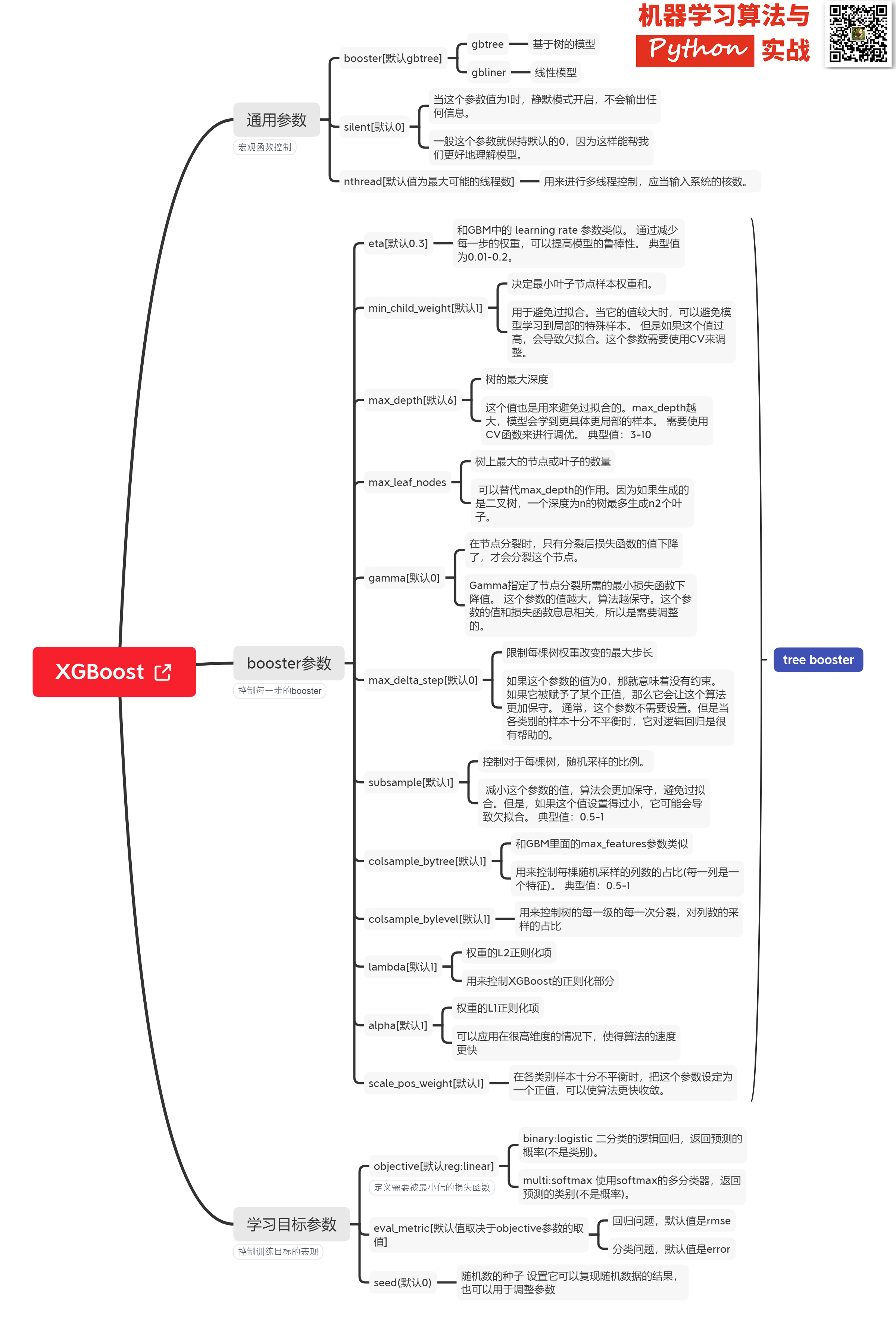
### Xgboost@sklearn模型参数解析
XGBoost的实现有原生版本,同时也有Scikit-learn版本,两者在使用上有一些微差异,这里给出xgboost.sklearn 参数解释。XGBoost使用**key-value**字典的方式存储参数:
```
#部分重要参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 10, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 12, # 构建树的深度,越大越容易过拟合
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样
'min_child_weight': 3,
'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed': 1000,
'nthread': 4, # cpu 线程数
}
```
篇幅原因,调参实例及XGBoost可视化且听下回分解。
如有收获,还请不吝给个**在看、收藏、转发**
## 参考
https://www.cnblogs.com/pinard/p/10979808.html
https://www.biaodianfu.com/xgboost.html
https://www.zybuluo.com/vivounicorn/note/446479
https://www.cnblogs.com/chenjieyouge/p/12026339.html